
Ever wondered why they even teach us these computer architectures?
Back in the early days
Any machine in the world has an architecture that demonstrates how its components work together to perform the output of the process intended. Back in the early days of June 30 till the early July 1945, the great mathematician John von Neumann, who was able to divide two eight-digit numbers in his head in seconds when he was a six-year-old child, introduced the foundational idea of what would later be known as the Von Neumann Architecture in the document he wrote “First Draft of a Report on the EDVAC” during his work on the ENIAC project. The idea he introduced simply was the stored program concept it’s an idea built on the idea the great mathematician Alan Turing introduced in his paper on 1936: The Universal Turing Machine it’s basically a computer that can make many other computers’ work. John Von Neumann took the idea into practice through building a computer that stores the program instructions electronically instead of hardwiring it to perform another process requires another set of instructions. Historically, the computers before built on the concept of the fixed-program, their functions was very specific and they couldn’t be reprogrammed, that is once a computer is constructed to do a modulus operation it is a modulus computer till the doomsday. But with the idea of the stored-program, we can reprogram the machine to do any other process again and again by executing any of the stored instructions in the machine without greasing our hands to change the machine to perform a new task. As the ideas in the First Draft evolved, they gave rise to see the final product of the Von Neumann Architecture.
Von Neumann Architecture
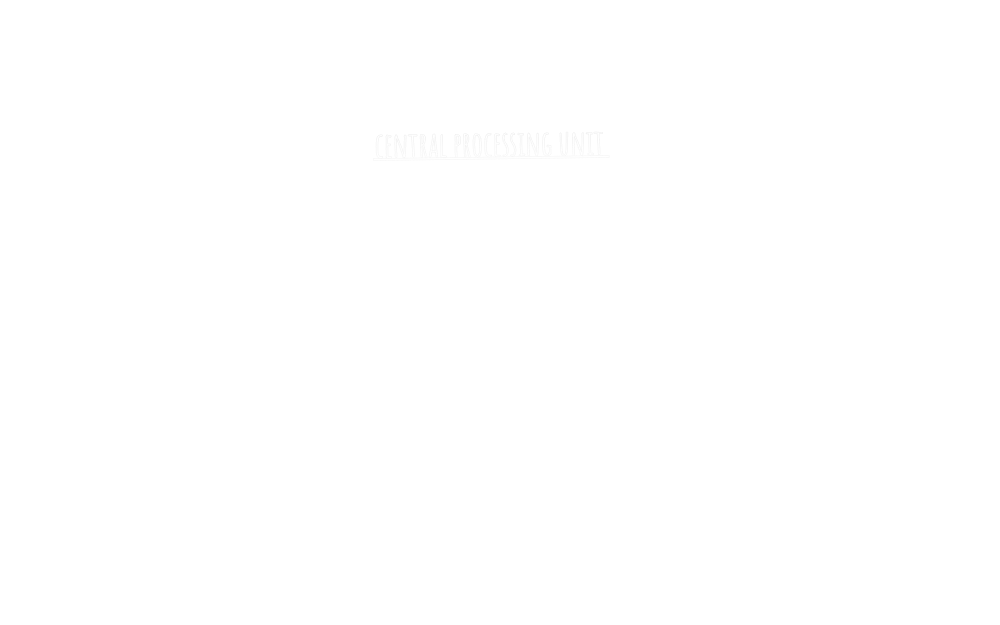
The idea was very simple: any program we want to execute will be stored as instructions in a memory unit, thus the CPU can fetch it them then decode them (configure some of the logic gates, turn them on/off) since every instruction in the computer is stored in 1s and 0s every bit has it’s work to activate and disactivate some gates configuring the logic gates inside the CPU, then the instruction is executed. Suppose you have a simple addition program that does a + b = c, you would need to load a to the memory then load b, add them, then write the results back to c, therefore what the program will actually do is something like this
;Fetch instruction LOAD a
;Decode instruction LOAD a ;CPU is now configured to execute this instruction
;Execute instruction LOAD a (Fetch the data at address "a" to the accumulator)
;Fetch instruction LOAD b
;Decode instruction LOAD b ;CPU is now configured to execute this instruction
;Execute instruction LOAD b (Fetch the data at address "b" ADDing it to the accumulator)
;Fetch instruction STORE c
;Decode instruction STORE c ;CPU is now configured to this instruction
;Execute instruction STORE, (Fetch the result of the accumulator the address "c" in the memory)
; Feel free to consider the accumulator as a storage unit for arithmetic operations inside the CPU if you're not familiar with itNow the program above is broken down and stored in the memory unit as fixed-size blocks called words. A word used to represent an instruction or data. When the word is transferred to the CPU, it is either decoded as an instruction or used directly as data. The structure of a word varies, but the core idea remains the same. If this sounds a little complicated, no worries. We’ll explore it more deeply in another post. For now, just think of any program as a set of instructions on data that need to be transferred into the CPU.
So as we said everytime we need to do an instruction on some data we are going to transfer the word that contains the instruction then the word that contains the data value from the memory unit to the CPU sequentially through a so-called bus? (the arrows between the CPU and the memory unit is actually a memory bus), therefore the CPU can perform the instructions on the data.
Actually, this works pretty well and the job is done, until you realize that we are running into several issues.
- As you’ve seen in the figure above there is only one bus to transfer both the instructions and the data, thus we can’t transfer them together only one of them, this is known as the Von Neumann bottleneck to understand why it is considered a limitation suppose there is a program that performs many instructions and write their results back to the memory, if you fetched an instructions and it’s data then processed the result, you are now ready to fetch the new instructions, Well! this won’t happen because the bus you want to use to fetch the new instructions is used to send the data back into the memory! The instructions and the data are competing for the bus resulting a traffic jam.
- Hence there is a unified memory this means that the instructions and the data are stored alongside with each other this poses a risk of memory corruption where the CPU accidentally write back the data in the address of an instruction.
So far, you’ve been exposed to the main limitations of the Von Neumann architecture. Now, take a moment and think about how you might solve the two problems we’ve discussed above? Maybe you will think in a clever idea and say you’d split this irritating unified memory into two separate units: one for instructions and one for data. That way, no more bottlenecks or memory corruptions.
Hold on! genius! you’ve just literally introduced the Harvard Architecture. What a genius!
Harvard Architecture
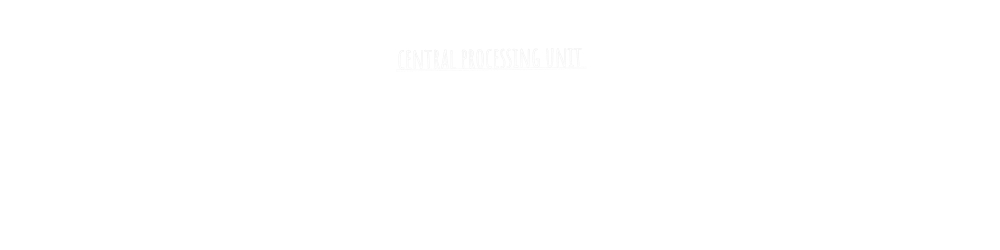
The core idea behind Harvard architecture was the idea that came in your mind separating the unified memory in the Von Neumann architecture into two separate parts one for storing the instruction that you will perform on the data only, and the other is for the data, this small detail changed the game.
Now let me introduce you to another problem from the never ending problems in the drawer, maybe you’ll be able to crack it for us again.
Now the problem is that there’s a latency occurs when transferring the word from any of these memory units to the CPU. This delay mainly kicks in due to many factors one of them which we will focus on is the physical distance as there’s a physical distance between the CPU and the memory unit, the further they are, the higher the propagation delay? gets, What would you do in this case? I can hear you saying it’s straight forward, just move the memory units closer to the CPU, here we are again! thanks for introducing us to the Modified Harvard Architecture
Modified Harvard Architecture
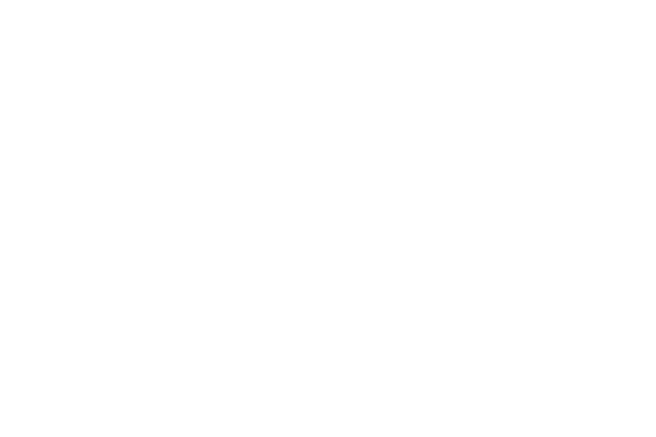
Modified Harvard Architecture is a variation of the Harvard Architecture generally we can consider it the undelying architecture of all of the modern machines today it can be described as a mix between the two architectures we’ve just listed: the Von Neumann and Harvard Architecture, the core idea is storing some instructions and data in the two memory units near the CPU and some instructions and data is going to be in a unified memory away from the CPU in this way what is actually happening is the CPU will fetch the words from the nearby memory if it didn’t find it, it will fetch it from the further memory (If you are familiar with caching you will find what I am saying here is very familiar to what you know about caching, actually this architecture is what caching is fundamentally built upon) if you are not familiar with that don’t worry it’s our topic for the next post.
Now in the late days..
You can skip this part entirely if you want it doesn’t have anything to do with the blog, this is just some ranting about what’s in my mind
..lying on the couch, holding our phones, talking about what thousands of genius minds have built over the course of maybe two hundred years of relentless effort since Charles Babbage delivered the world’s first mechanical computer through his Difference Engine all the way to this insanely complex thing we now casually hold in our hands the mobile you aren’t supposed to know all of this actually we’re not archives we’re not meant to store everything but if you’re wondering how knowing this topic and all of these things could help you in the real world well I’d say if you go like ‘Okay, computers run on Modified Harvard architecture, so why’s some data close to the CPU and some are not, why not all of them?’ this will introduce you to the caching which has a significant impact in the real worlds application or knowing the Von Neumann bottleneck that will make you cautious when accessing the main memory so next time you will write a program which access the main memory you would want to avoid them, so maybe you will dive deep and learn about what are the the solutions that prevent these bottlenecks and allowing you to access the memory safely like knowing the memory accessing practices aka the memory accessing modes so you you basically leveled up technically (but the actual learning that I really see here is your question itself here where the real learning comes, when you urge to learn more, dive deep and that non-stop digging)
the problems above makes you look at the classifications differently instead of always trying to find the best one you start to see them from a new perspective not as a ranking bad to good but as a series of tradeoffs like maybe the propagation delay is good sometimes when I don’t want the data to be accessed rapidly thus Von-Neumann architecture is very good in this case (and this is what you got the mentality) and actually it is a solution in the Modern Harvard Architecture as without it implementing this architecture would be very costly we will know about this more in a new post talking about memory types.
So let me boil it down for you, if the only thing you got from this blog is that you need to learn more, then congrats! you just learned everything you were supposed to learn from it
Almost forgot to show you this, for the ones who vibe with old relics XD
